SEO担当者が知っておきたいrobots.txt・noindexタグ・canonicalタグの使い分け解説

みなさんこんにちは。トビラマーケティングの伊藤です。高単価商品専門マーケターとして活動しており、SEOが1番得意な手法です。コーポレートサイトの検索順位を20位から1位に上げた実績などがあります。
今回はSEO対策で必要不可欠なrobots.txt(検索エンジンのクローラーへの指示を記述したファイル)・noindexタグ・canonicalタグ(URL正規化のためのタグ)の使い分け方法について解説していきます。
例えばSUUMOのようなサイトでは、物件を探すため様々な条件で絞り込みができます。つまり言い換えるとそれだけ大量のURLが生成されてしまいます。URLが大量に生成される≒クローラーが読み込みにくいサイトなので、クローラーが読み込みやすいよう制御する必要があります。この際に使われるのがrobots.txt・noindexタグ・canonicalタグです。
robots.txt・noindexタグ・canonicalタグについて誤った知識で対応してしまうと、逆に検索エンジンからの評価を下げかねません。クローラーにサイトを正しく読み込んでもらうため、robots.txt・noindexタグ・canonicalタグをどのように使い分けるか解説していきます。
検索エンジンの処理手順
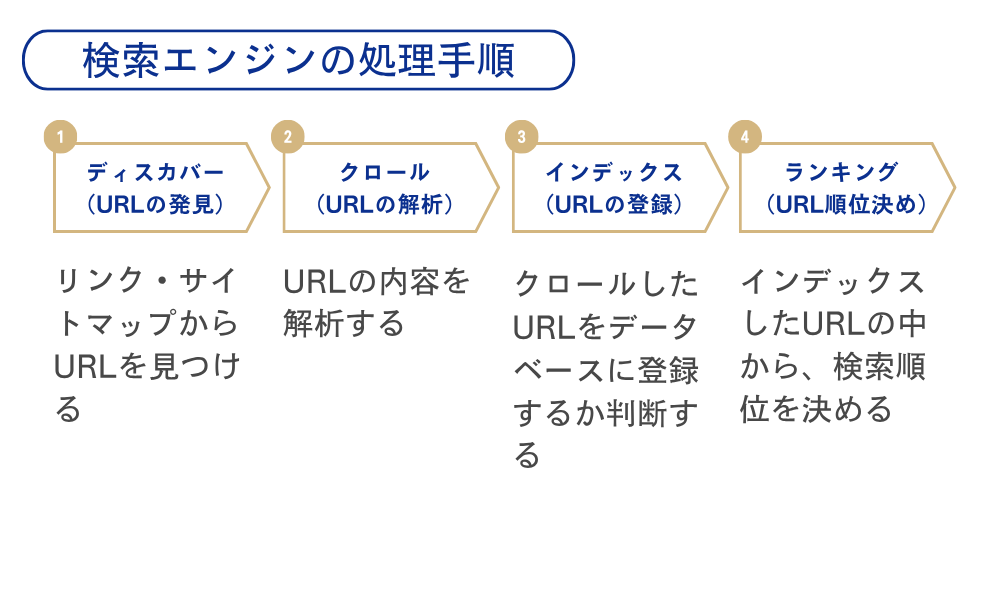
robots.txt・noindexタグ・canonicalタグの使い分けについて理解するためには、まず検索エンジンの処理手順について理解しておく必要があります。検索エンジンの処理手順についてはJADEさんの記事「検索インタラクションモデル概論-JADEが日々使うSEO分析フレームワークの話」の中のDCIRモデルがわかりやすいです。
- Discover(ディスカバー):URLの発見
- Crawl(クロール):URLの解析
- Index(インデックス):URLの登録
- Rank(ランキング):URLの順位付け
検索順位にページが表示されるためには、まずURLを発見してもらい、その後解析・登録を経て、はじめて順位付けが実施されます。つまり「なかなか検索順位に表示されない」という悩みに対して「リライトして記事の質を上げましょう」という回答は、間違っている可能性があります。
そもそもその記事がディスカバー・クロール・インデックスされていなければ、ランキング対象には入りません。インデックスされていない記事をリライトしても、インデックスされないままです。つまりリライトをする前に、どうすればURLを発見・解析・登録してもらえるかを考える必要があります。
また先述したようにインデックスされているURLが多すぎても、クローラーはサイトに対して正しい評価ができません。そのためSEO担当者は『どのURLを優先してディスカバー・クロール・インデックスしてもうか制御して、クローラーにわかりやすいサイト構成を伝える』ことが仕事になります。
クローラー制御方法
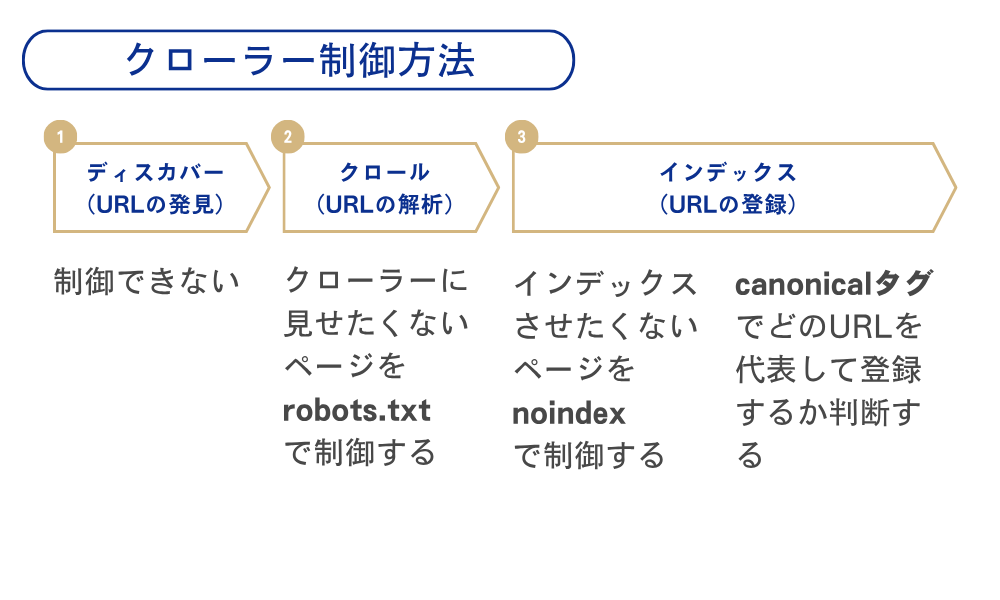
先ほど紹介したDCIRモデルを元に、クローラーをどのように制御していくか解説してきます。
まずディスカバーの段階ですが、この段階でクローラーは制御できません。クローラーはリンクやサイトマップをたどってURLを見つけます。新しいURLを見つけたら、どんなURLなのかクロールしていきます。
そしてクロールの段階でrobots.txtによる制御が可能です。robots.txtはクローラーに見せたくないページを制御する仕組みです。例えば開発用ページは訪問者に見せるべきページではないので、クロールしてもらいたくありません。そのためrobots.txtを使い、開発用ページをすべて制御するという命令を出します。クローラーはサイト解析時まずrobots.txtを読み込むので、robots.txtで制御されていればクロール自体をやめてくれます。このようにまずrobots.txtによって、クローラーを制御します。
続いてはインデックスの段階です。ここではnoindexタグとcanonicalタグによる制御ができます。noindexタグは特定ページをインデックスさせないために使います。robots.txtはクロール自体を止めるという命令に対し、noindexはインデックスを止めるという命令です。この使い分けについては、後ほど詳しく解説します。
canonicalタグは同じようなページが複数存在する場合、どのURLを代表して登録するか判断するために使います。例えばTシャツを販売するECサイトで、白・黒・青・赤の4つのページが存在したとします。その場合どのページを代表して登録するか命令しないと、似たようなページが複数存在すると認識され、サイトの評価が下がる可能性があります。そのため白・黒・青・赤の4つのページそれぞれにcanonicalタグを設定し、白Tシャツのページを代表して登録してくださいと命令を出します。これにより4ページの評価は白Tシャツページに集約され、クローラーがサイトを読み込みやすくなります。
このようにそれぞれの段階で、クローラーを制御する方法が用意されています。ページごとにどのようにクローラーを制御するか考え、ページに反映させていくと、サイトの評価が上がっていきます。
以上が概念上の制御手段です。では具体的に自社サイトではどのページを制御すべきか、次で確認してみましょう。
クローラーで制御するページの見つけ方
ここまでの前提知識を踏まえて、クローラーをどのように制御していくか解説していきます。クローラー制御に利用するのはGoogle Search Consoleです。Search Consoleのインデックス作成>ページを見ると、以下のようなページが表示されます。
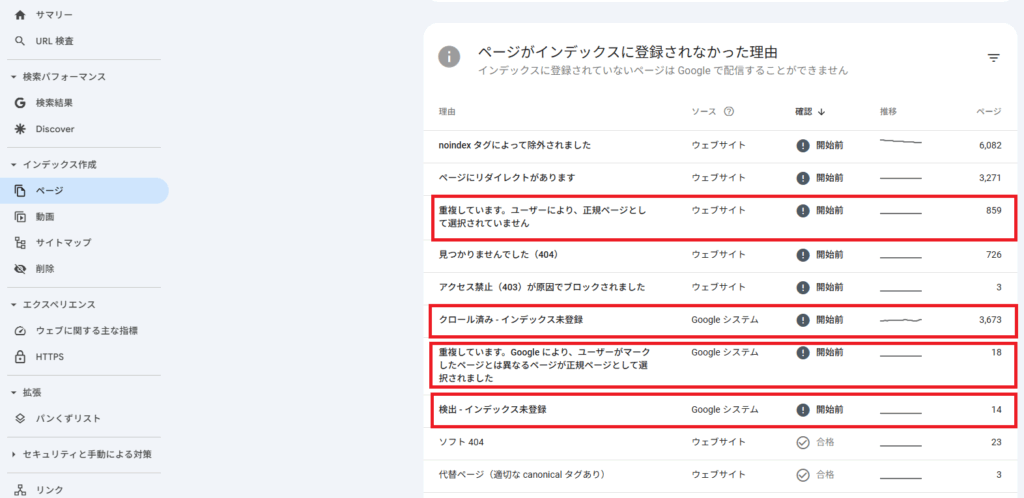
優先して取り組むのは「検出-インデックス未登録」「クロール済-インデックス未登録」にあるページ。その次に対処すべきなのが、重複に関するページです。それぞれの項目をクリックすると、具体的なURLを見ることができます。
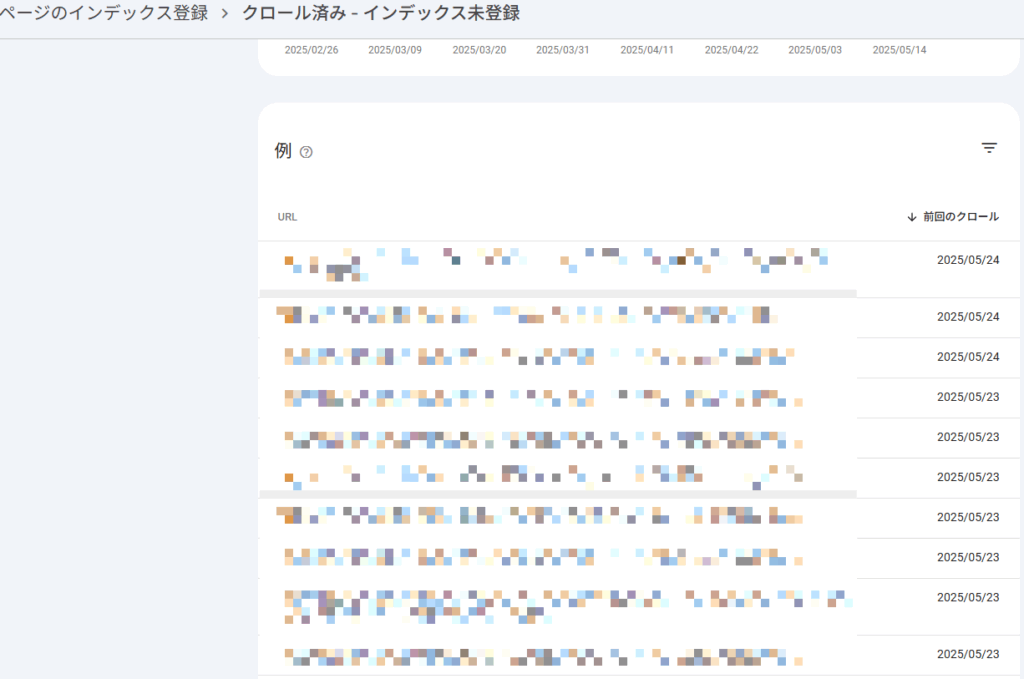
- 検出-インデックス未登録:ページをディスカバーしたが、クロールしていないページ(クロールの手前で止まっている)
- クロール済-インデックス未登録:ディスカバー・クロールはしたが、インデックスしていないページ(インデックスの手前で止まっている)
- 重複ページ:クロールされていて、正規ページに評価が渡されているページ(インデックスの手前で止まっている)
つまりこれらに該当しているページはクロール・インデックスされていないにも関わらず、クローラーのリソースを使っているURLと言えます。そのためSEO担当者としては以下のような作業が必要になります。
- 「クロール済-インデックス未登録」の一覧をチェックする
- そもそもクロール・インデックス不要なページを見つける
- 不要なページにrobots.txtやnoindexタグで制御をかけ、クローラーが読み込まない・インデックスしない設計にする
- クローラーは必要なページだけ巡回すればよくなり、クロール効率が上がる
- クロール効率が上がった結果サイト評価が上がり、検索順位上昇が期待できる
このようにクローラーの制御はサイト評価・検索順位にも関わるとても重要な作業です。それぞれどのような作業をすればいいか、正しく理解しておきましょう。
robots.txtの使い方
クローラーの具体的な制御方法、まずはrobots.txtの使い方について解説してきます。robots.txtはクローラーに見せたくないページを伝えるファイルです。Webサイトを作る際には基本的に設置されており、Google Search Consoleからもrobots.txtがどんな設定になっているか確認できます。

robots.txtにはこのようなテキストが記述されています。テキストの意味は以下の通りです。
- User-agent: * … すべてのロボットに対して
- Disallow: /admin/ … /admin/以下はクロール禁止
- Disallow: /test/ … /test/以下も禁止
このように管理画面やテストページなど、クローラーに見せたくないページをディレクトリ単位で一括制御できます。クローラーはまずrobots.txtを確認するので、robots.txtで指定されたURLはクローラーの閲覧対象から外れます。
robots.txtの利用例
robots.txtはディレクトリ単位で制御する命令です。そのため以下のようなページはrobots.txtに記述しておきます。
- /dev/や/test/など開発・テスト用ページ
- /admin/など管理用ページ
このようにディレクトリ単位でクロールしてほしくないページをrobots.txtに記述していきます。「検出-インデックス未登録」「クロール済-インデックス未登録」で発見したURLの中にディレクトリ単位で制御したほうがいいURLを発見した場合は、robots.txtファイルへの記述を実行しましょう。
noindexタグの使い方
続いてはnoindexタグの使い方です。ページ単位でインデックスさせたくないページに、noindexタグを挿入します。

このようなタグをページ内に挿入することで、そのページのインデックスを制御します。
またnoindexと合わせて記述されるのがfollowもしくはnofollowという表記です。
- noindex, follow:検索結果には出したくないが、内部リンク評価は渡したい場合
- noindex, nofollow:検索結果にも出さず、リンクも評価してほしくない場合
このようにリンクを評価してほしいかどうかでfollowもしくはnofollowの記述を変更します。
noindexタグの利用例
noindexタグを利用するページとしては、以下のようなページが挙げられます。
- タグ一覧ページ
- 404エラーページ
- 印刷用ページ
- お問い合わせページ
このようにインデックス不要のページには、noindexタグの記述をしていきます。Search Consoleの「検出-インデックス未登録」「クロール済-インデックス未登録」に表示されているページは、Googleがクロール・インデックスする価値が低いと判断したページです。その中からインデックス不要のページをリストアップして、noindexタグを記述していきましょう。
canonicalタグの使い方
Search Consoleで重複ページと判定されたページには、canonicalタグの設定を実行します。canonicalタグとは「このページの正規版はここですよ」と検索エンジンに伝えるタグです。重複・類似ページが複数存在するするときに、Googleに「どのURLを評価すべきか」を示すために使います。canonicalタグが設定されていないと、こちらの意図と違ったページが検索結果に表示されてしまいます。
canonicalタグの利用例
canonicalタグは色違いのTシャツのページが複数あった場合などに利用します。
- 白Tシャツ https://example.com/product/tshirt-white
- 黒Tシャツ https://example.com/product/tshirt-black
canonicalタグを設定しないと、評価が分散してかつどのページが検索結果に表示されるかわかりません。そこで白Tシャツのページを正規URLと決めて、黒Tシャツページに以下のようなタグを挿入します。

hrefに検索評価を集めたい正規URLを指定します。上記の場合であれば「このページ(黒Tシャツ)の評価を白Tシャツのページに集約してください。」という指示が送られます。そうすると白Tシャツページに評価が集約され、検索結果に表示されるのも白Tシャツページになります。
Search Consoleで表示された重複ページに対して、正しくcanonicalタグを設定することで、クロール効率を上げていきます。
robots.txt・noindexタグ・canonicalタグのまとめ表
| 項目 | robots.txt | noindexタグ | canonicalタグ |
| 主な利用目的 | クロール制御(巡回させない) | インデックス制御(登録させない) | 評価の統合(重複ページの正規化) |
| 指定単位 | ディレクトリ単位orページ単位 | ページ単位 | ページ単位 |
| クロールされるか | ✖:原則クロールされない | 〇:クロールされる | 〇:クロールされる |
| インデックスされるか | ✖:ただし外部リンクなどによりURLのみインデックスされる可能性あり | ✖:インデックスされない | 〇:インデックスされるが、評価はcanonical先に集約される |
| リンク評価 | 通常どおり | follow/nofollowの設定次第 | 評価はcanonical先に集約される |
robots.txt・noindexタグ・canonicalタグについてよくある質問
- robots.txtで指定されているページにnoindexタグを入れる必要はありますか?
-
robots.txtで指定されているページにnoindexタグは不要です。robots.txtで指定された時点でクロール対象から外れています。robots.txtで指定してさらにnoindexタグでクロールを禁止すると、クローラーがページを読めずnoindexが認識されないという逆効果にもなってしまいます。
- canonicalタグを指定すれば重複ページは自動的にインデックスされなくなりますか?
-
いいえ。canonicalタグはあくまで推奨URLを伝えるだけなので、Googleが必ず採用するとは限りません。確実にインデックスを避けたい場合は、noindexタグの利用を検討する必要があります。
- 大規模サイトのSEO対策をする場合、クローラー制御に関する知識は必須ですか?
-
必須です。近年爆発的にWebサイトの数が増えたことで、Googleのクロールバジェットにも限りがあります。そのためクローラー制御がうまくいっていないサイトは、順位が下落する可能性が高いです。検索順位が落ちた大規模サイトは、一度クローラー制御の見直しを実施することをおすすめします。
SEO対策の相談はトビラマーケティングへ
ここまでrobots.txt・noindexタグ・canonicalタグの使い分けについて解説してきました。特に大規模サイトではクロールの制御をしないと、クロール効率が落ち、検索順位下落につながってしまいます。ぜひ使い分け方を覚えて、サイト改修を進めていきましょう。
トビラマーケティングでは、サイトのクロール効率化も含めたSEO対策全般をお任せいただけます。
「サイト構成・クロール制御の相談をしたい」
「大規模サイトのSEO対策を実施してほしい」
という方は、ぜひお気軽にお問い合わせください。
トビラマーケティングのマーケティング支援メニュー
- マーケティング・SEO対策スポット相談(1時間3万円)
- マーケティング・SEO対策コンサル(月11万円)
- マーケティング・SEO施策実行支援(月22万円~)
「どのサービスに申し込めばいいかわからない」「詳しく話を聞いてみたい」という方は、無料相談も承っております。よろしれければ、そちらもご活用ください。









コメント